
Mirai unlocks the full power of Apple’s ANE and GPU, delivering best-in-class inference speed for small models.
Optimised for Apple Silicon
First 10,000 devices for free
CoreML compatible
Instant setup, no guesswork
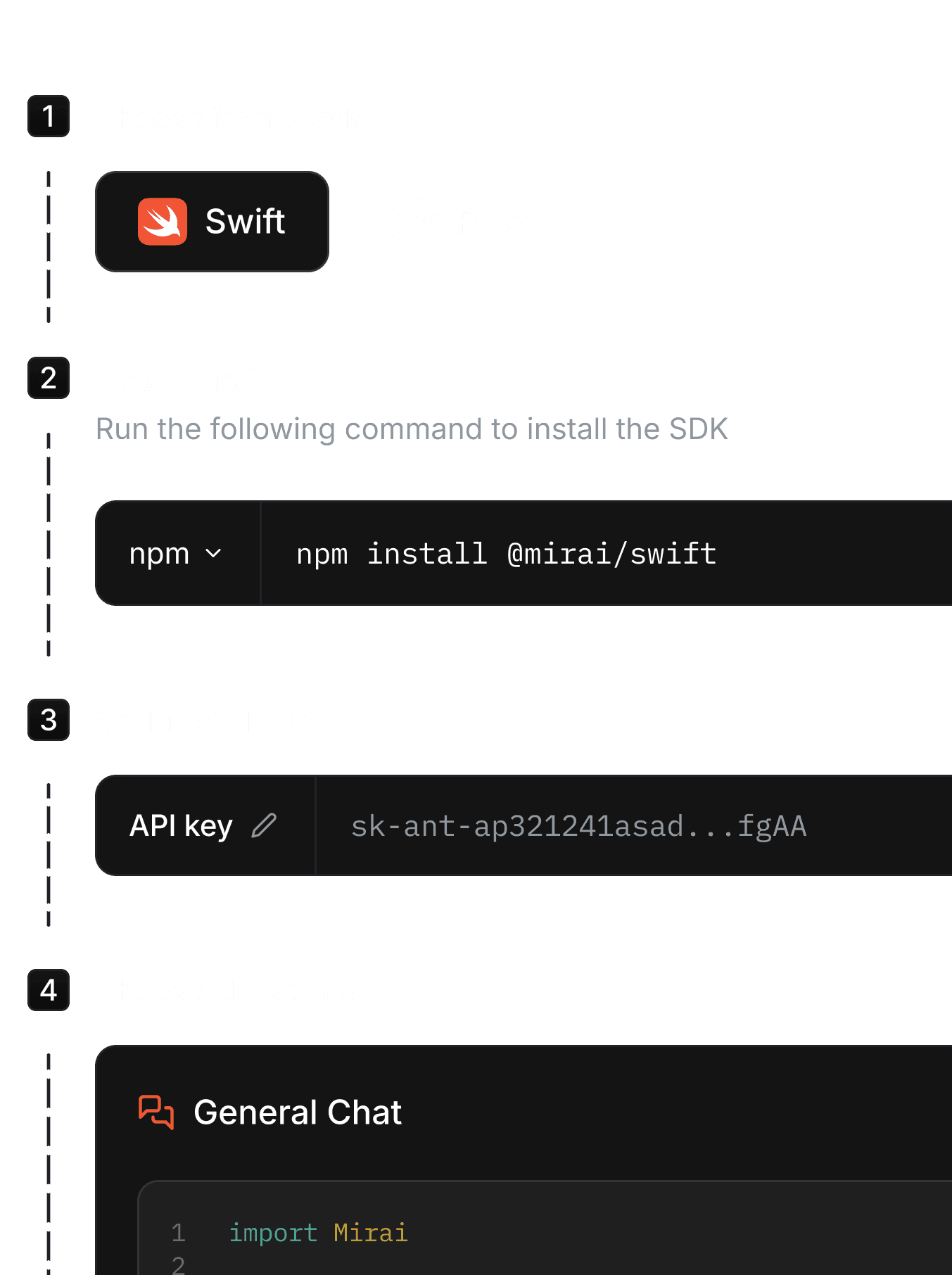
Pick a use case, choose the model, and drop into your code. Mirai handles quantization, fallback logic, and structured output
Purpose-built for Apple hardware & optimized to the limit
Fastest Inference on iOS
Benchmarked. Tuned. No unnecessary complexity
Simply choose a use case to start with

General Chat
Conversational AI, running on-device

Classification
Tag text by topic, intent, or sentiment

Summarisation
Conversational AI, running on-device

Custom
Build your own use case

Camera
Process images with local models
COMING SOON

Voice
Turn voice into actions or text
COMING SOON
First 10,000 used devices for free
Setup in less than 10 minutes
Full control and performance
Run most popular small LLMs
Reduce cloud costs up to n%
Up to 50% of queries will be handled locally
Perfect fit for
Messaging & assistants
Productivity & writing tools
Finance, health & compliance apps
On device intelligence layers
With Mirai SDK, creating and deploying on device AI is as easy as picking your framework (Swift or Rust), generating API key, and choosing use case

