
Exploring Metal Performance Primitives on any M-series chip
Exploring Metal Performance Primitives on any M-series chip
Apple shipped Metal Performance Primitives: a GPU matmul API built on cooperative_tensor.
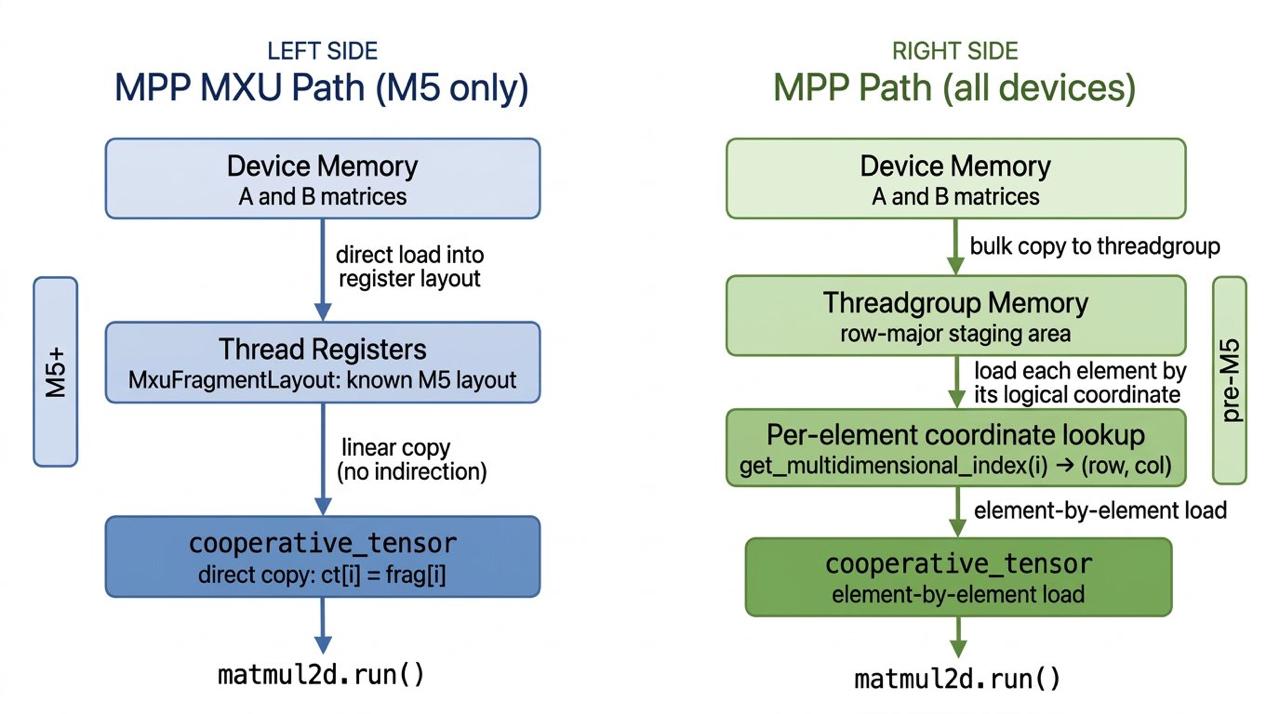
If you look at Apple's open-source code for an example of how to use MPP, you'll find a hardcoded M5 memory layout.
It loads data directly into registers matching that layout, then does a linear copy into the cooperative_tensor: ct[i] = frag[i].
Try running it on any pre-M5 chip and you get garbage.
Apple's spec says the layout is "device specific" and "opaque", but they never document what it actually is for any chip. So you'd reasonably conclude: MPP = M5 only.
But buried in the Metal Shading Language Spec there's a function on cooperative_tensor called get_multidimensional_index(i). It returns the logical (row, col) for element i. It works on every Apple Silicon generation. Here' the recipe for running MPP on any chip.
Step 1: query the layout once, cache it:
const short capacity = tensor.get_capacity(); for (short i = 0; i < capacity; i++) { auto coord = tensor.get_multidimensional_index(i); col[i] = coord[0]; row[i] = coord[1]; }
const short capacity = tensor.get_capacity(); for (short i = 0; i < capacity; i++) { auto coord = tensor.get_multidimensional_index(i); col[i] = coord[0]; row[i] = coord[1]; }
Step 2: load from threadgroup memory using the discovered coordinates:
for (short i = 0; i < capacity; i++) { tensor[i] = shared[(row_base + row[i]) * LD + col[i]]; } matmul_op.run(left, right, accumulator)
for (short i = 0; i < capacity; i++) { tensor[i] = shared[(row_base + row[i]) * LD + col[i]]; } matmul_op.run(left, right, accumulator)
All threads cooperatively load a tile into threadgroup memory first. Each simdgroup then reads its portion using the discovered layout.
Apple shipped Metal Performance Primitives: a GPU matmul API built on cooperative_tensor.
If you look at Apple's open-source code for an example of how to use MPP, you'll find a hardcoded M5 memory layout.
It loads data directly into registers matching that layout, then does a linear copy into the cooperative_tensor: ct[i] = frag[i].
Try running it on any pre-M5 chip and you get garbage.
Apple's spec says the layout is "device specific" and "opaque", but they never document what it actually is for any chip. So you'd reasonably conclude: MPP = M5 only.
But buried in the Metal Shading Language Spec there's a function on cooperative_tensor called get_multidimensional_index(i). It returns the logical (row, col) for element i. It works on every Apple Silicon generation. Here' the recipe for running MPP on any chip.
Step 1: query the layout once, cache it:
const short capacity = tensor.get_capacity(); for (short i = 0; i < capacity; i++) { auto coord = tensor.get_multidimensional_index(i); col[i] = coord[0]; row[i] = coord[1]; }
Step 2: load from threadgroup memory using the discovered coordinates:
for (short i = 0; i < capacity; i++) { tensor[i] = shared[(row_base + row[i]) * LD + col[i]]; } matmul_op.run(left, right, accumulator)
All threads cooperatively load a tile into threadgroup memory first. Each simdgroup then reads its portion using the discovered layout.
