
Apple Silicon’s GPU (starting from M5, with tensor cores / “neural accelerators”) has a fast W8A8 path. If both weights and activations are INT8, you can use it for prefill and speculative-decoding verification. Weights are easy. They’re static and can be quantized offline. Activations are the hard part: they change every token and have to be quantized on the fly, in the hot path.
And here’s the problem: LLM activations have outliers. A handful of channels blow up 10–100x past the rest, consistently, across tokens. If you’re computing a single scale factor for the whole token, those outlier channels eat the entire dynamic range. Everything else gets crammed into what’s left, which means you end up wasting most of your effective precision on values you barely care about.
Three levers:
You basically have three options:
Better scale / zero-point selection
Fix the distribution before quantizing
Use a different quantization scheme (per-channel, grouped)
Option 3 is the obvious fix. Per-channel quantization would handle this cleanly. But the hardware doesn’t cooperate. If you want the GPU’s fast W8A8 path, you need standard INT8 GEMM with a per-token scalar scale and zero-point. Move to per-channel dequantization and the work scales with channel count, you’re no longer on the simple INT8 matmul path.
So I left 3 alone and focused on 1 and 2. In the end, 2 did most of the work.
I’ll come back to 1.
The key insight: outliers are structured.
The outliers are structured. They aren't random spikes. The same channels keep showing up across tokens, which means you can do something geometric about them.
QuaRot (Ashkboos et al., 2024) uses this. Apply an online Hadamard rotation before each linear layer, and pre-rotate the weights so the layer output stays the same. Functionally, nothing changes. The rotation is orthogonal, so the model never knows, but the activation distribution gets a lot flatter. The offline part folds into the weights for free. The online Hadamard is O(n log n) per layer.
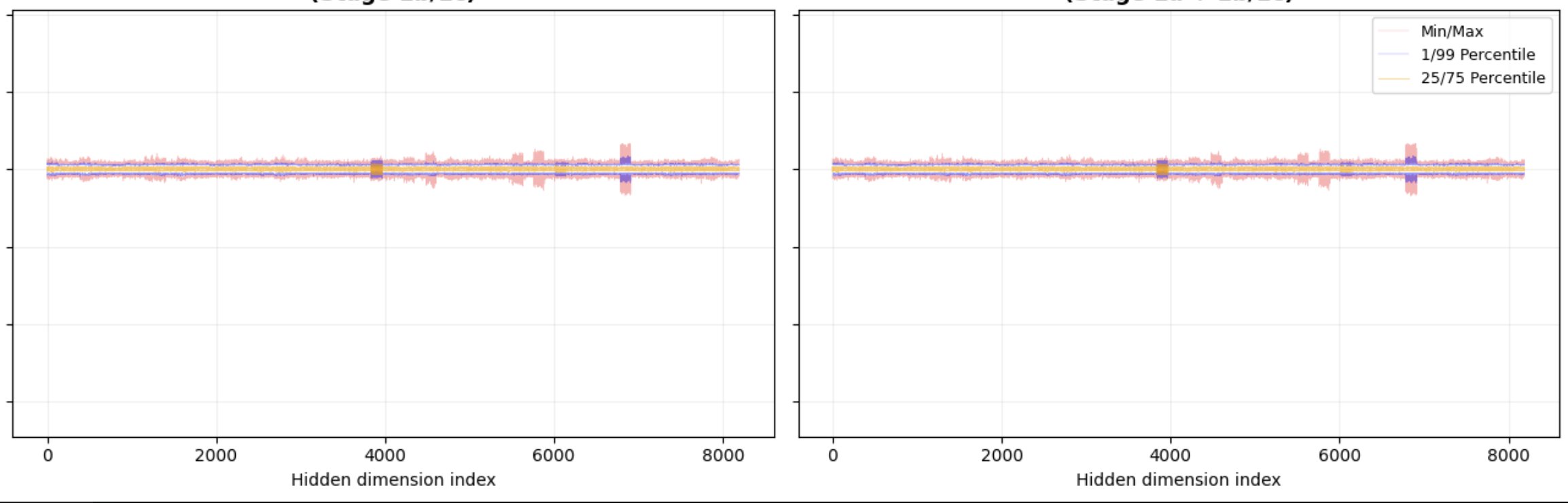
After rotation, no channel dominates. You go from a distribution with extreme tails to something approximately uniform, and a uniform distribution quantizes cleanly.
And once the activations are flat, a lot of other fixes stop having much to latch onto. More on that in a moment.
What I actually tried?
I tried this on LFM-1.2B. First pass was RHT (Stage 1a: offline residual-stream rotation) plus online Hadamard before the down/out projections (Stage 1b/1c). That got KL down to 0.006.
Then I implemented the full Kronecker factorization for attention outputs. QuaRot gives H = (I x H_dh)(H_nh x I) . The second factor mixes across heads, and that part turned out to matter. On top of that I used an iterative activation quantizer that refines scale and zero-point for 5 rounds.
Final numbers:
naive INT8 AQ | 0.015 nats KL |
Stage 1a + 1b/1c | 0.006 |
Kronecker + iter. AQ | 0.002 |
What didn’t work?
After the rotation, I went back and tried to push option 1 harder: diagonal Hessian weighting (diag(WᵀW)), Fisher-weighted quantization, low-rank SVD error correction. Basically nothing moved.
The reason is intuitive in hindsight. Hessian-based methods are designed to handle non-uniform sensitivity across dimensions. Weight some channels higher, others lower, based on how much each affects the output. But once the rotation has done its job, the Hessian is close to uniform. All channels contribute roughly equally. There’s nothing to differentiate.
SmoothQuant-style per-channel scaling has the same problem. After rotating, the scaling gets smeared back across channels and the smoothing mostly disappears.
Rotation and Hessian-weighting aren’t additive. They attack the same underlying problem from different angles. Once you’ve applied one well, the other has diminishing returns. The rotation has already solved the problem the Hessian was trying to solve.
What’s next?
The rotation approach works well for activations.
Longer term, the more interesting problem at Mirai is how far this extends when you’re optimizing the full stack: inference runtime, conversion tooling, and model architecture together. Post-training quantization in isolation is one thing. Co-optimizing quantization with the model itself is a different problem, and it’s the one we’re actually working on.
More on that soon.
