


Outpeforming
Apple MLX

llama.cpp
Built for model makers
Extend your model beyond the cloud
Built for developers
Easily integrate modern AI pipelines into your app
Free 10K Devices
Try Mirai SDK for free
Drop-in SDK for local + cloud inference.
Model conversion + quantization handled.
Local-first workflows for text, audio, vision.
One developer can get it all running in minutes.

All major SOTA models supported
Build real-time AI experiences with on-device inference
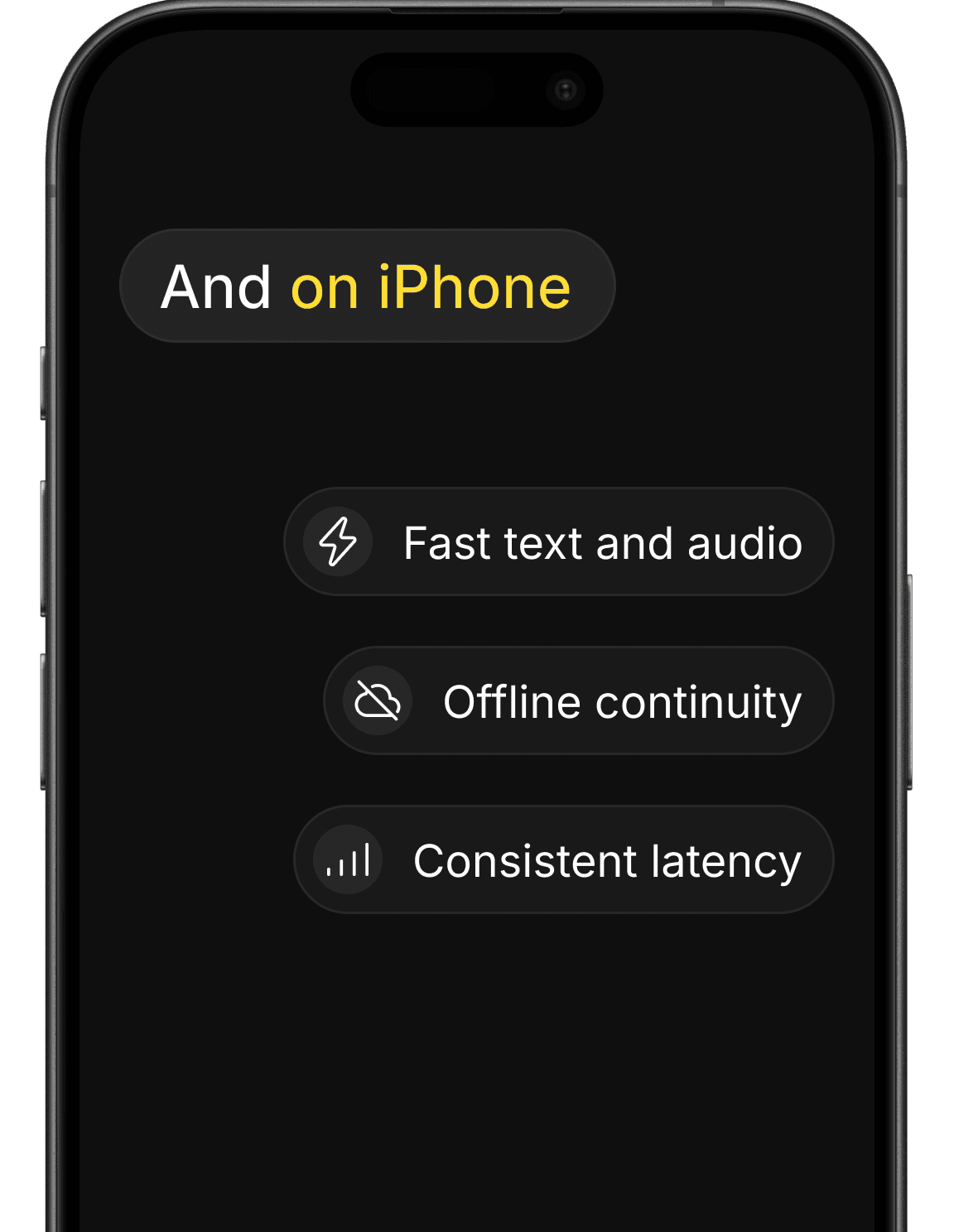
Users don’t care where your model runs. They care how it feels.
Fast responses for text and audio.
Offline continuity. No network, no break.
Consistent latency. Even under load.

We’ve partnered with Baseten to give you full control over where inference runs. Without changing your code
Free your cloud.
Run your models locally
Deploy and run models of any architecture directly on user devices

