LiquidAI/LFM2-1.2B
Run locally on Apple devices with Mirai
- Type
- local
- From
- LiquidAI
- Quantization
- No
- Parameters
- 1.2B
- Size
- 2.2 GB
- Source


LFM2-1.2B is a 1.2-billion-parameter hybrid language model from Liquid AI, purpose-built for edge AI and on-device deployment. Part of the second-generation LFM family, it combines a novel architecture of multiplicative gates and short convolutions — specifically 10 double-gated short-range LIV convolution blocks and 6 grouped query attention (GQA) blocks — to deliver strong quality at minimal resource cost.
Key Strengths
- Speed — 3× faster training than the previous LFM generation; 2× faster CPU decode and prefill compared to Qwen3.
- Quality — Outperforms similarly-sized models across knowledge, math, instruction following, and multilingual benchmarks.
- Flexible deployment — Runs efficiently on CPU, GPU, and NPU hardware, targeting smartphones, laptops, and vehicles.
The model supports a 32,768-token context window and eight languages: English, Arabic, Chinese, French, German, Japanese, Korean, and Spanish. It was trained on 10 trillion tokens (≈75% English, 20% multilingual, 5% code) using knowledge distillation from LFM1-7B, large-scale supervised fine-tuning, custom DPO, and iterative model merging.
Benchmarks
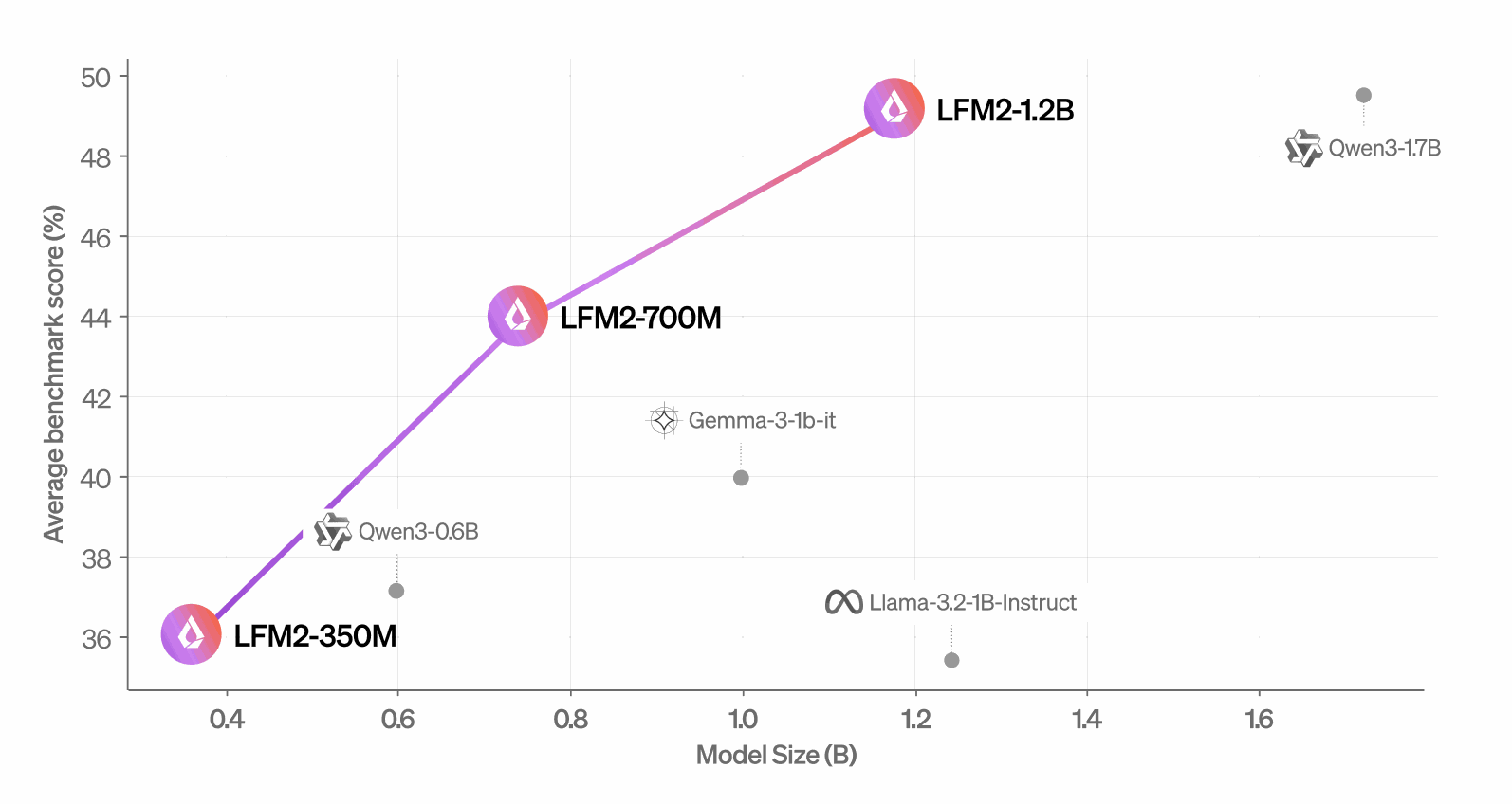
LFM2-1.2B leads or closely matches larger competitors on automated evaluations including MMLU, GPQA, IFEval, and MGSM.
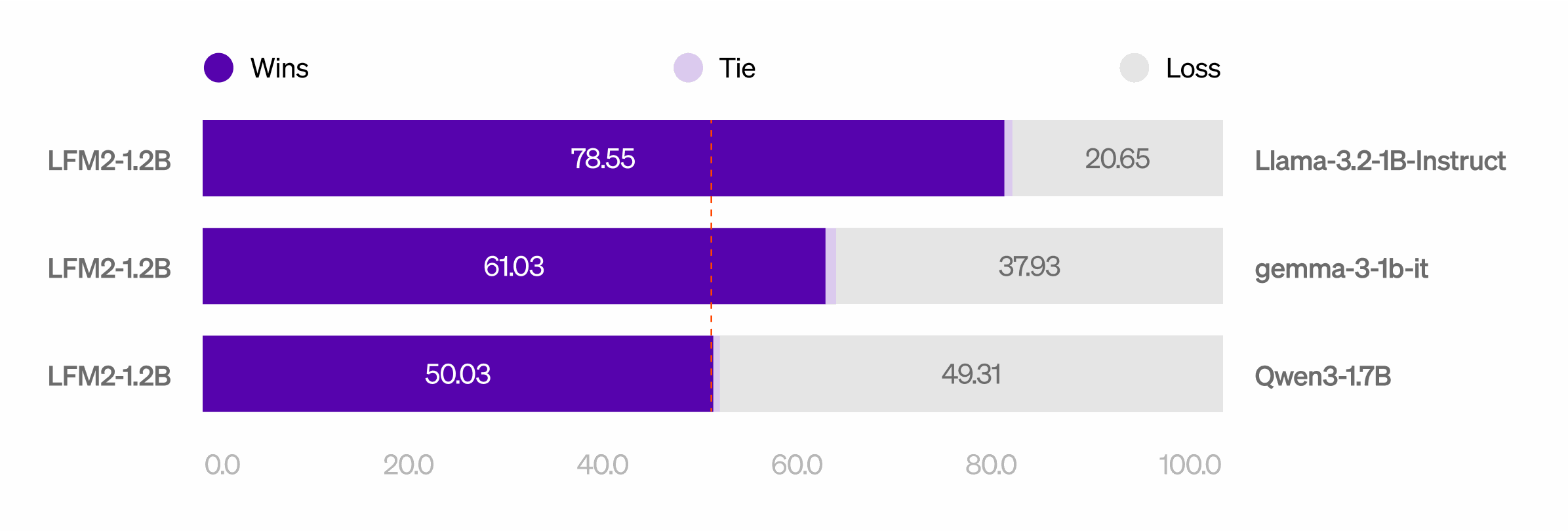
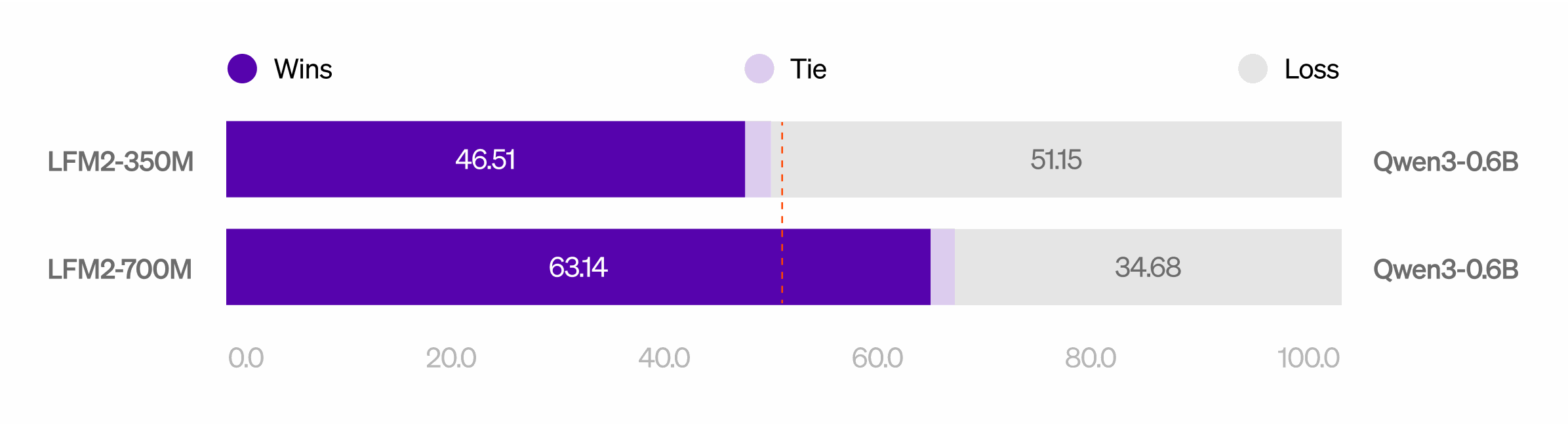
LLM-as-a-Judge evaluations confirm strong conversational and instruction-following quality relative to its size class.
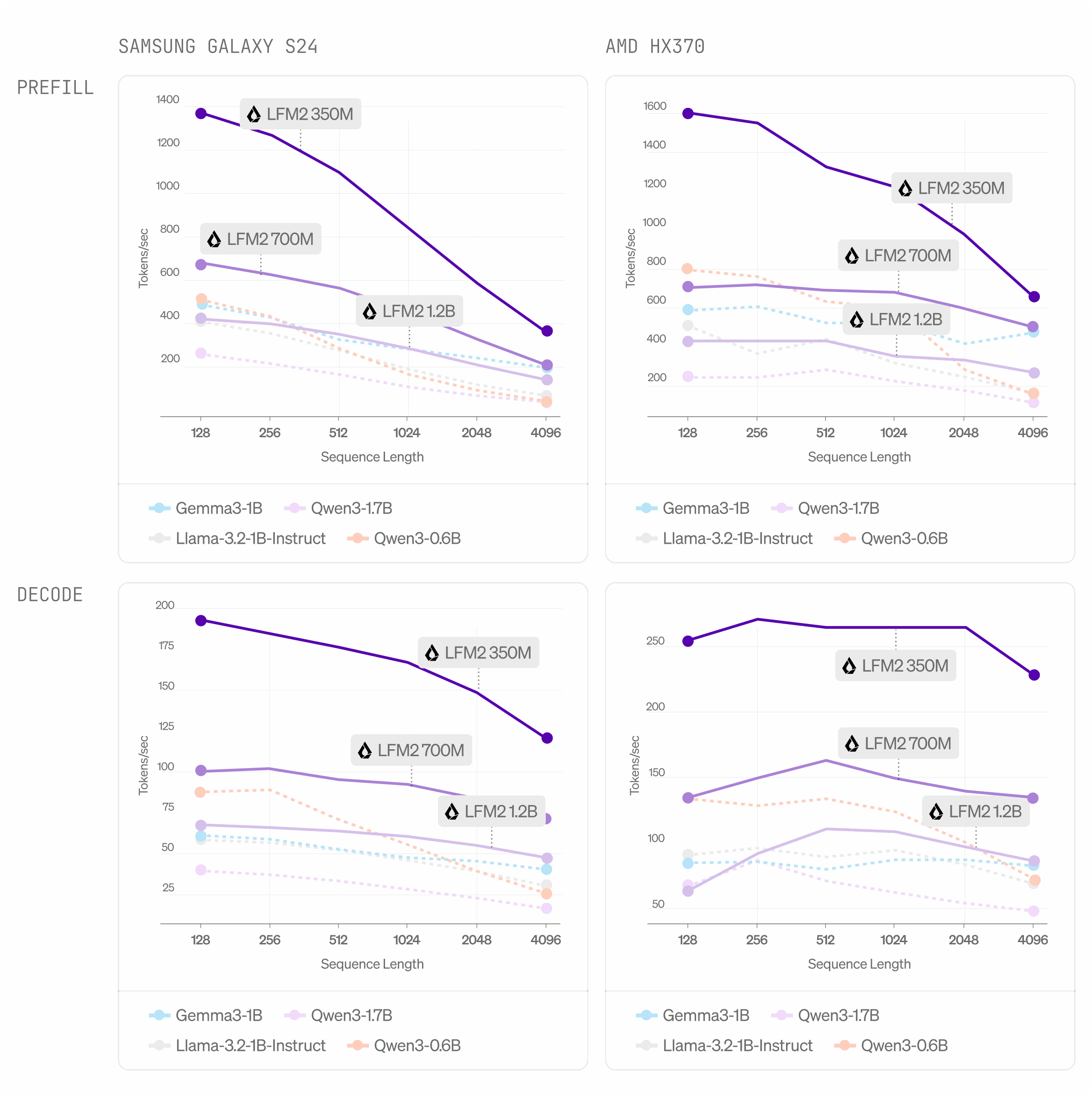
Inference Performance
On-device throughput tests show clear advantages on CPU runtimes like ExecuTorch and llama.cpp.
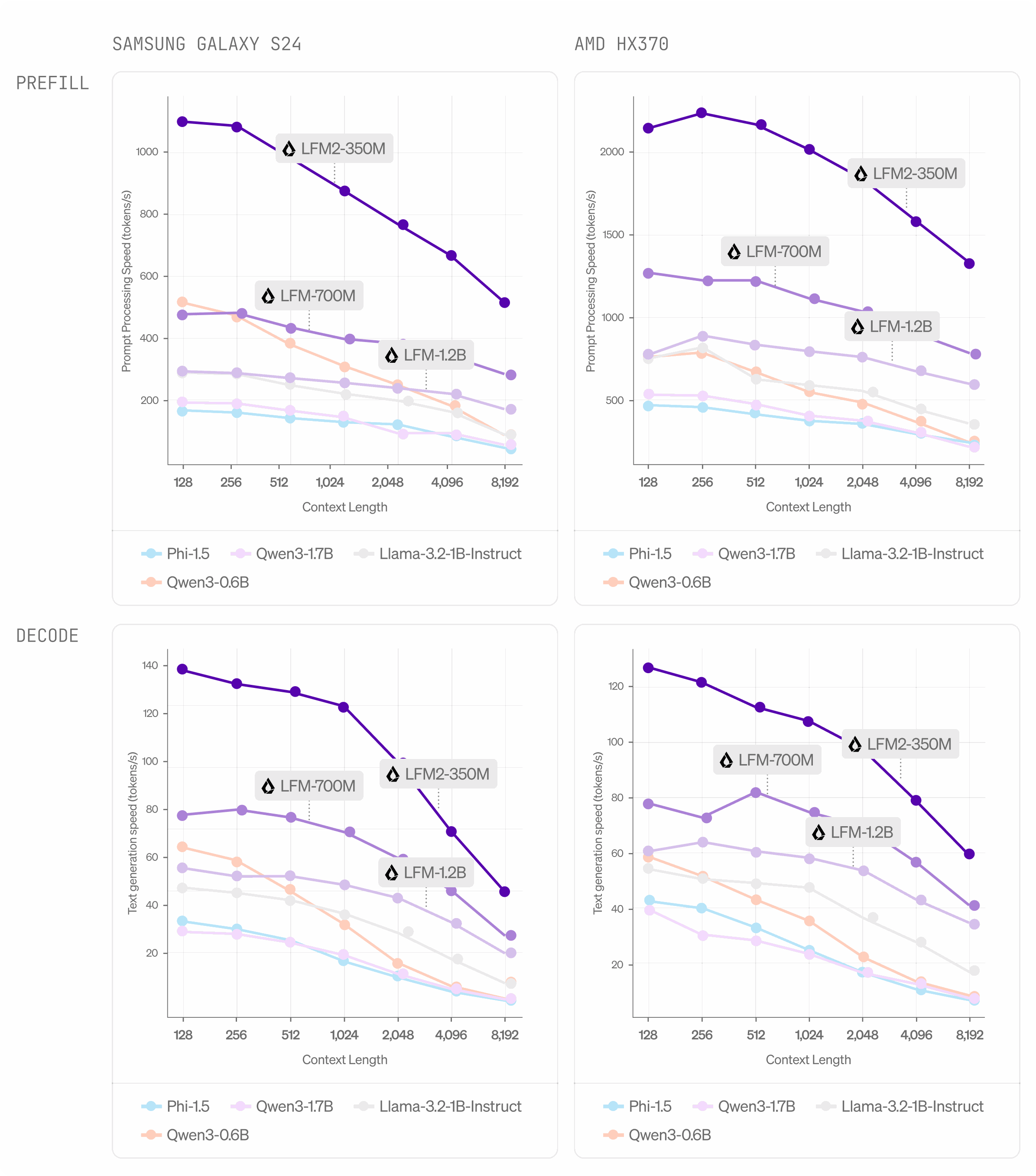
Recommended Use Cases
Due to its compact size, Liquid AI recommends fine-tuning LFM2-1.2B on focused tasks for best results. It excels at agentic workflows, data extraction, RAG, creative writing, and multi-turn conversations. Built-in tool-use support enables structured function calling via a ChatML-style template. Compatible with Hugging Face Transformers (v4.55+), vLLM, and llama.cpp via GGUF.
spm https://github.com/trymirai/uzu.git
| 1 | import Uzu |
| 2 | |
| 3 | public func runChat() async throws { |
| 4 | let engineConfig = EngineConfig.create() |
| 5 | let engine = try await Engine.create(config: engineConfig) |
| 6 | |
| 7 | guard let model = try await engine.model(identifier: "LiquidAI/LFM2-1.2B") else { |
| 8 | return |
| 9 | } |
| 10 | for try await update in try await engine.download(model: model).iterator() { |
| 11 | print("Download progress: \(update.progress())") |
| 12 | } |
| 13 | |
| 14 | let messages = [ |
| 15 | ChatMessage.system().withText(text: "You are a helpful assistant"), |
| 16 | ChatMessage.user().withText(text: "Tell me a short, funny story about a robot") |
| 17 | ] |
| 18 | let session = try await engine.chat(model: model, config: .create()) |
| 19 | let stream = await session.replyWithStream(input: messages, config: .create()) |
| 20 | var message: ChatMessage? = nil |
| 21 | for try await update in stream.iterator() { |
| 22 | switch update { |
| 23 | case .replies(let replies): |
| 24 | message = replies.last?.message |
| 25 | case .error(let error): |
| 26 | print("Error: \(error)") |
| 27 | } |
| 28 | } |
| 29 | print("Text: \(message?.text() ?? "empty")") |
| 30 | } |