LiquidAI/LFM2-2.6B
Run locally on Apple devices with Mirai
- Type
- local
- From
- LiquidAI
- Quantization
- No
- Parameters
- 2.6B
- Size
- 4.8 GB
- Source


LFM2-2.6B is the flagship model in Liquid AI's second-generation family of hybrid language models, purpose-built for edge AI and on-device deployment. With 2.6 billion parameters trained on 10 trillion tokens, it delivers strong quality-per-parameter across knowledge, math, instruction following, and multilingual tasks — while staying efficient enough to run on CPUs, GPUs, and NPUs in smartphones, laptops, and vehicles.
Architecture
LFM2 introduces a novel hybrid design combining multiplicative gates with short convolutions. The 2.6B variant uses 30 layers — 22 double-gated short-range LIV convolution blocks and 8 grouped query attention (GQA) blocks — supporting a 32,768-token context window. This architecture enables 2× faster decode and prefill on CPU compared to similarly sized competitors.
Capabilities
LFM2-2.6B is the only model in the LFM2 family to support dynamic hybrid reasoning, producing chain-of-thought traces for complex or multilingual prompts. It also features structured tool use via JSON function definitions and Pythonic function calls.
The model supports eight languages: English, Arabic, Chinese, French, German, Japanese, Korean, and Spanish. It is particularly well-suited for agentic tasks, data extraction, RAG, creative writing, and multi-turn conversations. Liquid AI recommends fine-tuning on narrow use cases for best results.
Performance
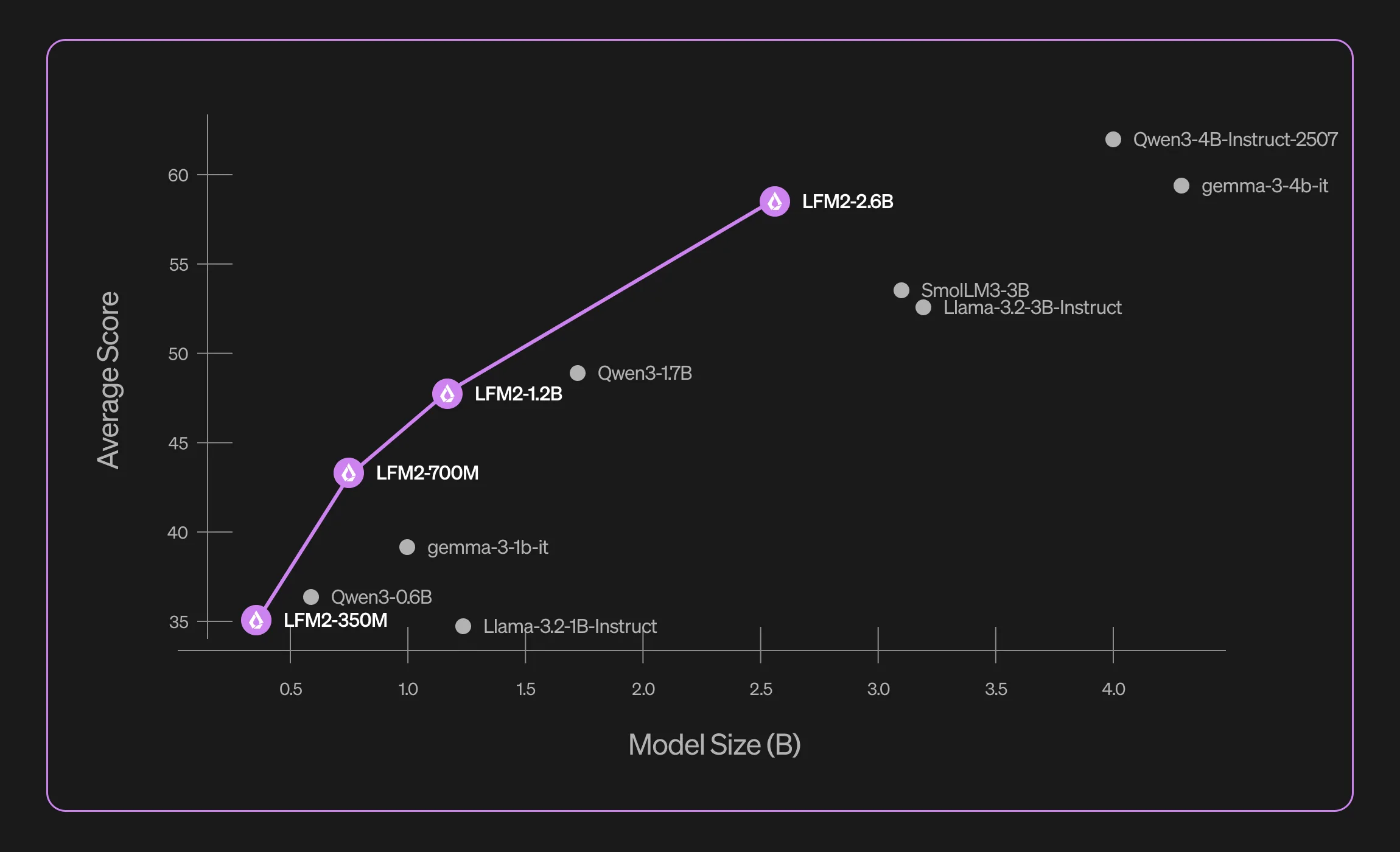
LFM2-2.6B outperforms Llama-3.2-3B-Instruct and SmolLM3-3B on MMLU (64.42), IFEval (79.56), GSM8K (82.41), and MGSM (74.32), establishing a strong quality baseline at the sub-3B scale.
Deployment & Fine-Tuning
The model is compatible with Hugging Face Transformers (v4.55+), vLLM, and llama.cpp via GGUF checkpoints. Fine-tuning is supported through SFT (with Unsloth or TRL) and DPO workflows, with ready-made Colab notebooks provided. Precision is bfloat16 under the LFM Open License v1.0.
spm https://github.com/trymirai/uzu.git
| 1 | import Uzu |
| 2 | |
| 3 | public func runChat() async throws { |
| 4 | let engineConfig = EngineConfig.create() |
| 5 | let engine = try await Engine.create(config: engineConfig) |
| 6 | |
| 7 | guard let model = try await engine.model(identifier: "LiquidAI/LFM2-2.6B") else { |
| 8 | return |
| 9 | } |
| 10 | for try await update in try await engine.download(model: model).iterator() { |
| 11 | print("Download progress: \(update.progress())") |
| 12 | } |
| 13 | |
| 14 | let messages = [ |
| 15 | ChatMessage.system().withText(text: "You are a helpful assistant"), |
| 16 | ChatMessage.user().withText(text: "Tell me a short, funny story about a robot") |
| 17 | ] |
| 18 | let session = try await engine.chat(model: model, config: .create()) |
| 19 | let stream = await session.replyWithStream(input: messages, config: .create()) |
| 20 | var message: ChatMessage? = nil |
| 21 | for try await update in stream.iterator() { |
| 22 | switch update { |
| 23 | case .replies(let replies): |
| 24 | message = replies.last?.message |
| 25 | case .error(let error): |
| 26 | print("Error: \(error)") |
| 27 | } |
| 28 | } |
| 29 | print("Text: \(message?.text() ?? "empty")") |
| 30 | } |