LiquidAI/LFM2.5-1.2B-Thinking
Run locally on Apple devices with Mirai
- Type
- local
- From
- LiquidAI
- Quantization
- No
- Parameters
- 1.2B
- Size
- 2.2 GB
- Source


LFM2.5-1.2B-Thinking is a compact reasoning model from Liquid AI, designed to bring high-quality AI inference to edge devices while running under 1GB of memory. Part of the LFM2.5 family, it builds on the LFM2 hybrid architecture with extended pre-training on 28 trillion tokens and multi-stage reinforcement learning.
Architecture & Specifications
The model features a hybrid design with 1.17B parameters across 16 layers — 10 double-gated LIV convolution blocks paired with 6 grouped-query attention (GQA) blocks. It supports a 32,768-token context window and a vocabulary of 65,536 tokens. Eight languages are supported: English, Arabic, Chinese, French, German, Japanese, Korean, and Spanish.
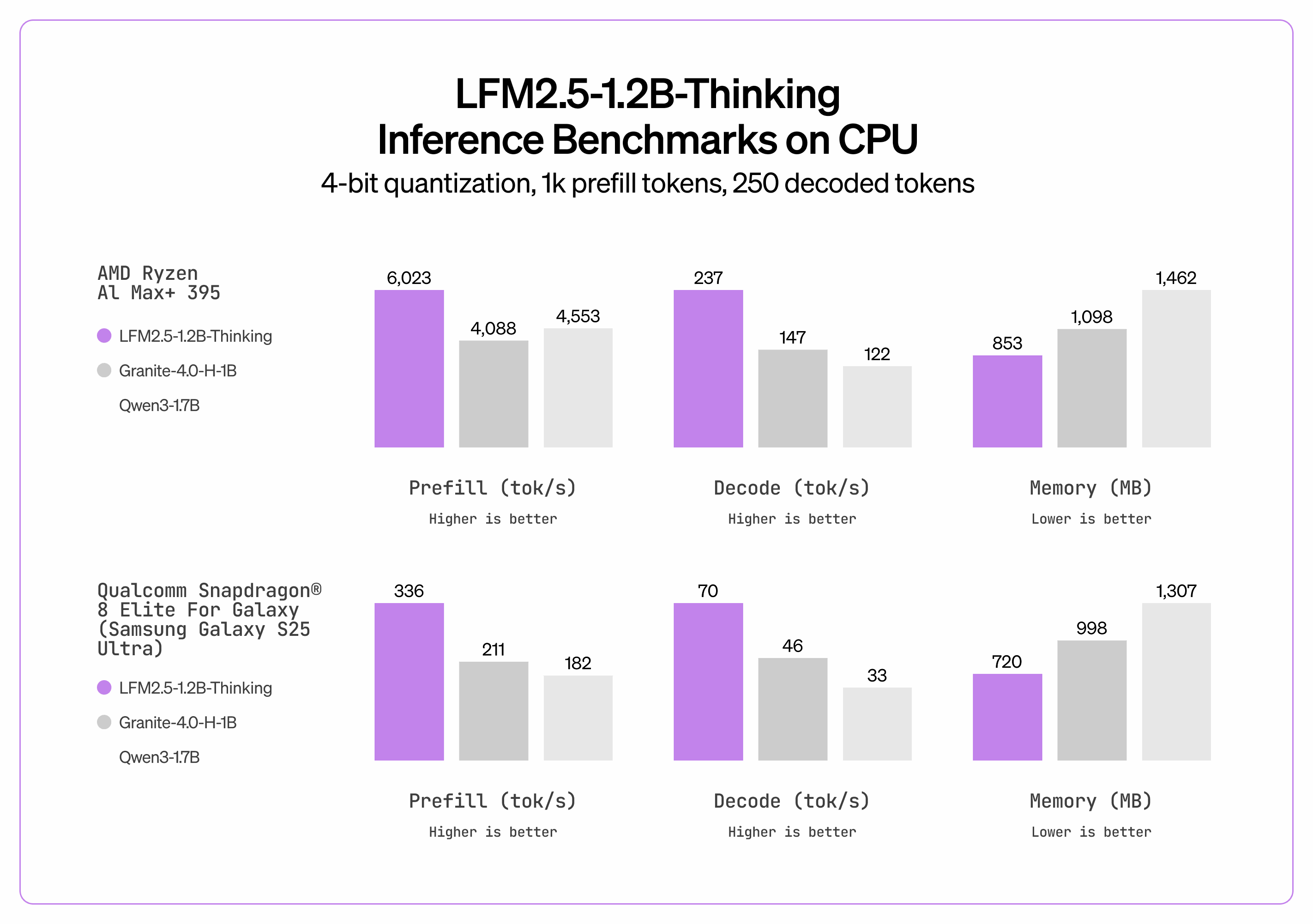
Performance & Speed
LFM2.5-1.2B-Thinking rivals much larger models on reasoning benchmarks, achieving strong scores on MATH-500 (87.96), IFEval (88.42), and GSM8K (85.60). On hardware, it delivers 239 tok/s decode on AMD CPU and 82 tok/s on mobile NPU, making it practical for real-time on-device applications.
Recommended Use Cases
Liquid AI recommends this model for agentic tasks, data extraction, and RAG workflows. It also supports structured function calling with Pythonic tool-use syntax. It is less suited for knowledge-intensive tasks or programming.
Deployment Options
The model ships in multiple formats for flexible deployment: native Transformers/vLLM checkpoints, GGUF for llama.cpp and CPU inference, ONNX for cross-platform hardware acceleration, and MLX for Apple Silicon. It also works with LM Studio for local desktop use. Fine-tuning is supported via Unsloth and TRL with LoRA, SFT, DPO, and GRPO recipes.
spm https://github.com/trymirai/uzu.git
| 1 | import Uzu |
| 2 | |
| 3 | public func runChat() async throws { |
| 4 | let engineConfig = EngineConfig.create() |
| 5 | let engine = try await Engine.create(config: engineConfig) |
| 6 | |
| 7 | guard let model = try await engine.model(identifier: "LiquidAI/LFM2.5-1.2B-Thinking") else { |
| 8 | return |
| 9 | } |
| 10 | for try await update in try await engine.download(model: model).iterator() { |
| 11 | print("Download progress: \(update.progress())") |
| 12 | } |
| 13 | |
| 14 | let messages = [ |
| 15 | ChatMessage.system().withText(text: "You are a helpful assistant"), |
| 16 | ChatMessage.user().withText(text: "Tell me a short, funny story about a robot") |
| 17 | ] |
| 18 | let session = try await engine.chat(model: model, config: .create()) |
| 19 | let stream = await session.replyWithStream(input: messages, config: .create()) |
| 20 | var message: ChatMessage? = nil |
| 21 | for try await update in stream.iterator() { |
| 22 | switch update { |
| 23 | case .replies(let replies): |
| 24 | message = replies.last?.message |
| 25 | case .error(let error): |
| 26 | print("Error: \(error)") |
| 27 | } |
| 28 | } |
| 29 | print("Text: \(message?.text() ?? "empty")") |
| 30 | } |