LiquidAI/LFM2.5-350M
Run locally on Apple devices with Mirai
- Type
- local
- From
- LiquidAI
- Quantization
- No
- Parameters
- 350M
- Size
- 680.8 MB
- Source


Liquid AI's LFM2.5-350M is a general-purpose instruction-tuned model from a new family of hybrid models designed specifically for on-device deployment. Building on the LFM2 architecture, it leverages extended pre-training and large-scale multi-stage reinforcement learning to deliver best-in-class performance, rivaling much larger models and bringing high-quality AI directly to edge devices.
Architecture & Specifications
LFM2.5-350M features 350 million parameters distributed across 16 layers (10 double-gated LIV convolution blocks and 6 GQA blocks). It was trained on an extensive budget of 28T tokens (scaled up from 10T tokens) and supports a generous 32,768 token context length. The model has a vocabulary size of 65,536 and a knowledge cutoff of Mid-2024.
Performance
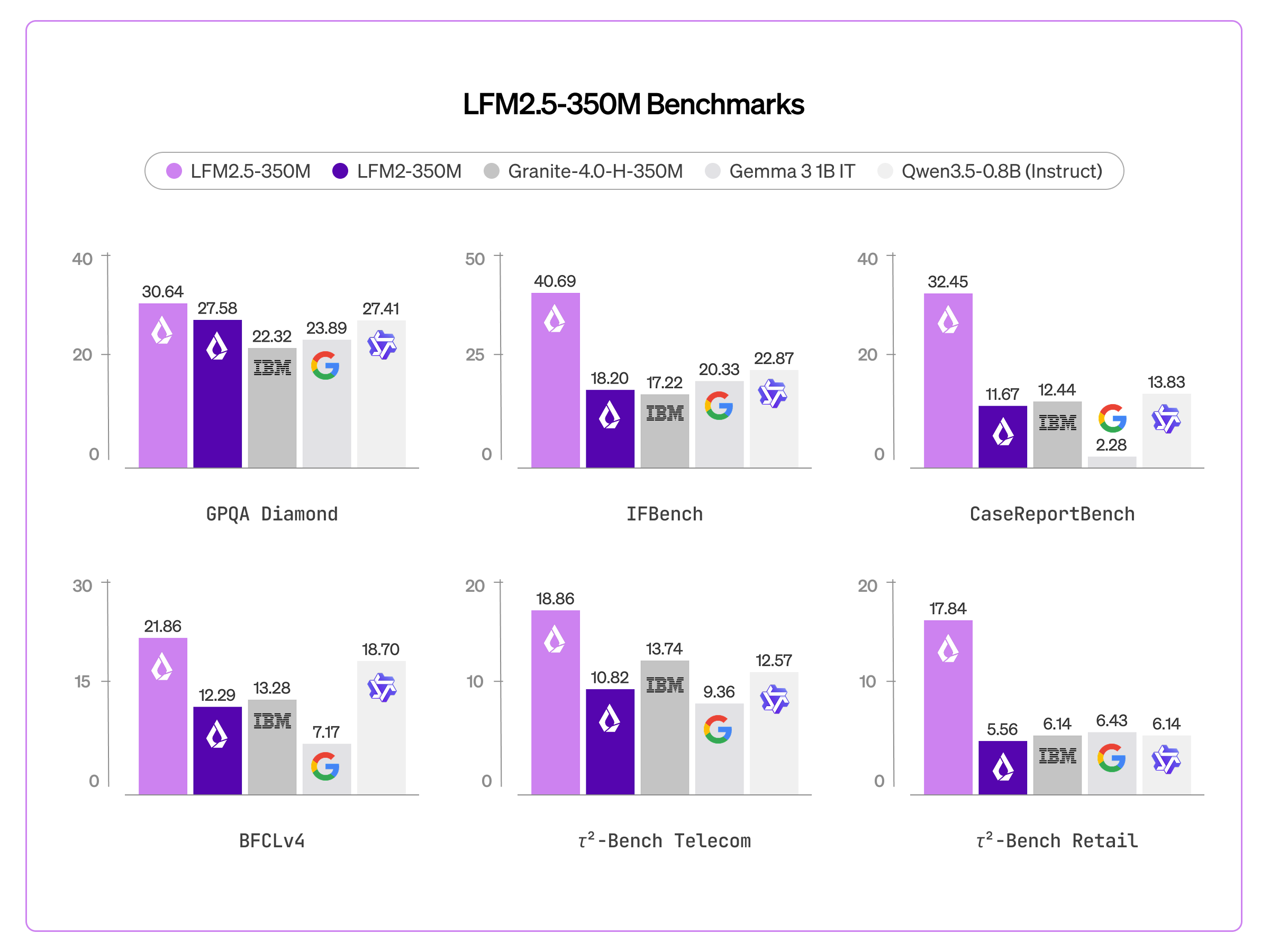
LFM2.5-350M leads its class across a wide range of benchmarks. On general reasoning and instruction-following tasks it scores 30.64 on GPQA Diamond, 40.69 on IFBench, and 44.92 on Multi-IF — outperforming comparable models such as Gemma 3 1B IT and Granite 4.0-H-350M. On agentic and tool-use benchmarks it achieves 32.45 on CaseReportBench, 44.11 on BFCLv3, and leads in τ²-Bench Telecom (18.86) and τ²-Bench Retail (17.84), substantially ahead of all listed competitors.
Inference
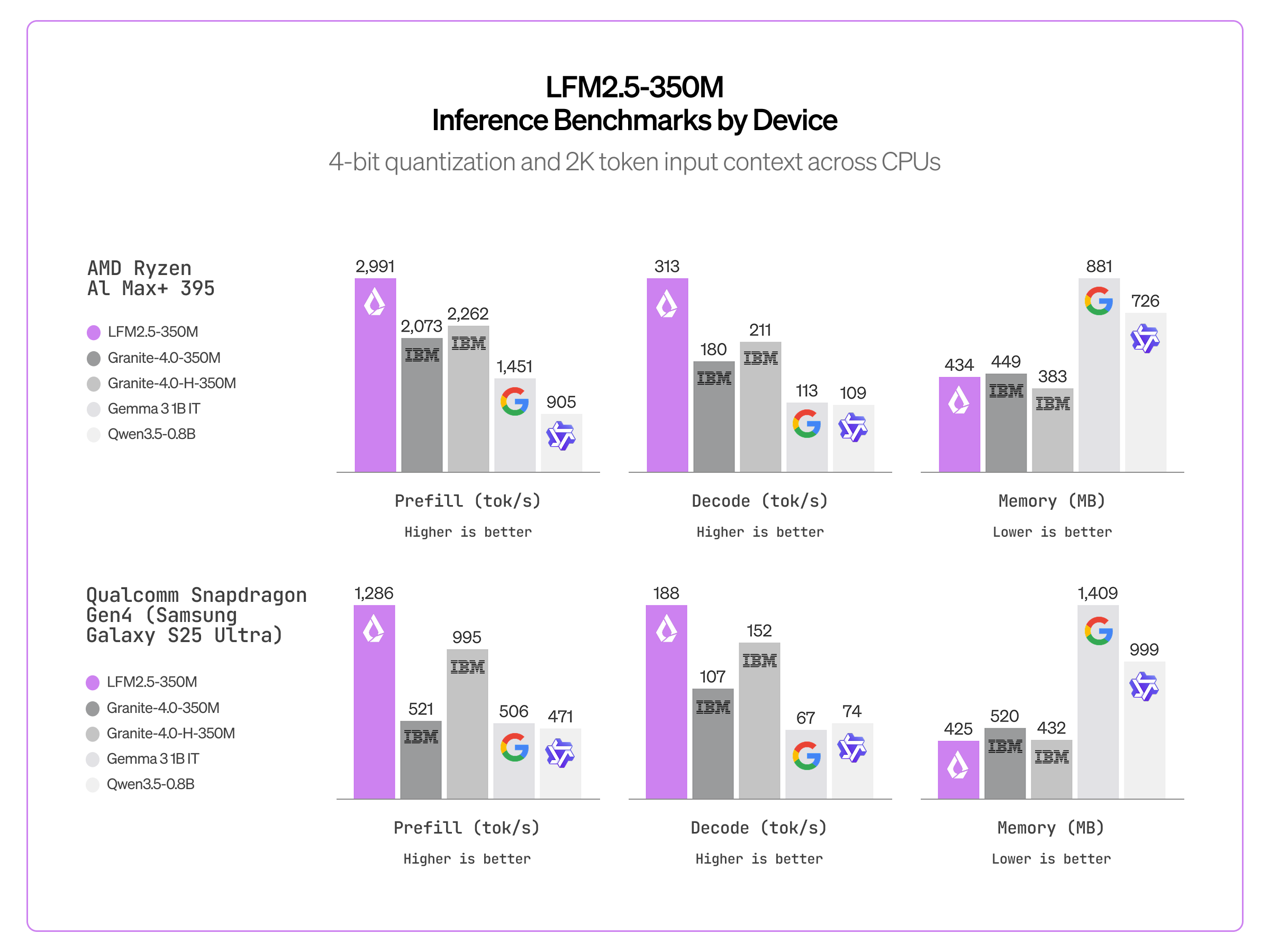
LFM2.5-350M is highly optimized for fast edge inference. Under 4-bit quantization with a 2K token input context, it achieves 2,991 tok/s prefill and 313 tok/s decode on an AMD Ryzen AI Max+ 395, and 1,286 tok/s prefill and 188 tok/s decode on a Qualcomm Snapdragon Gen4 (Samsung Galaxy S25 Ultra). Memory usage on both devices is under 450 MB, making it the most memory-efficient model in its class. It runs with day-one support for llama.cpp, MLX, and vLLM.
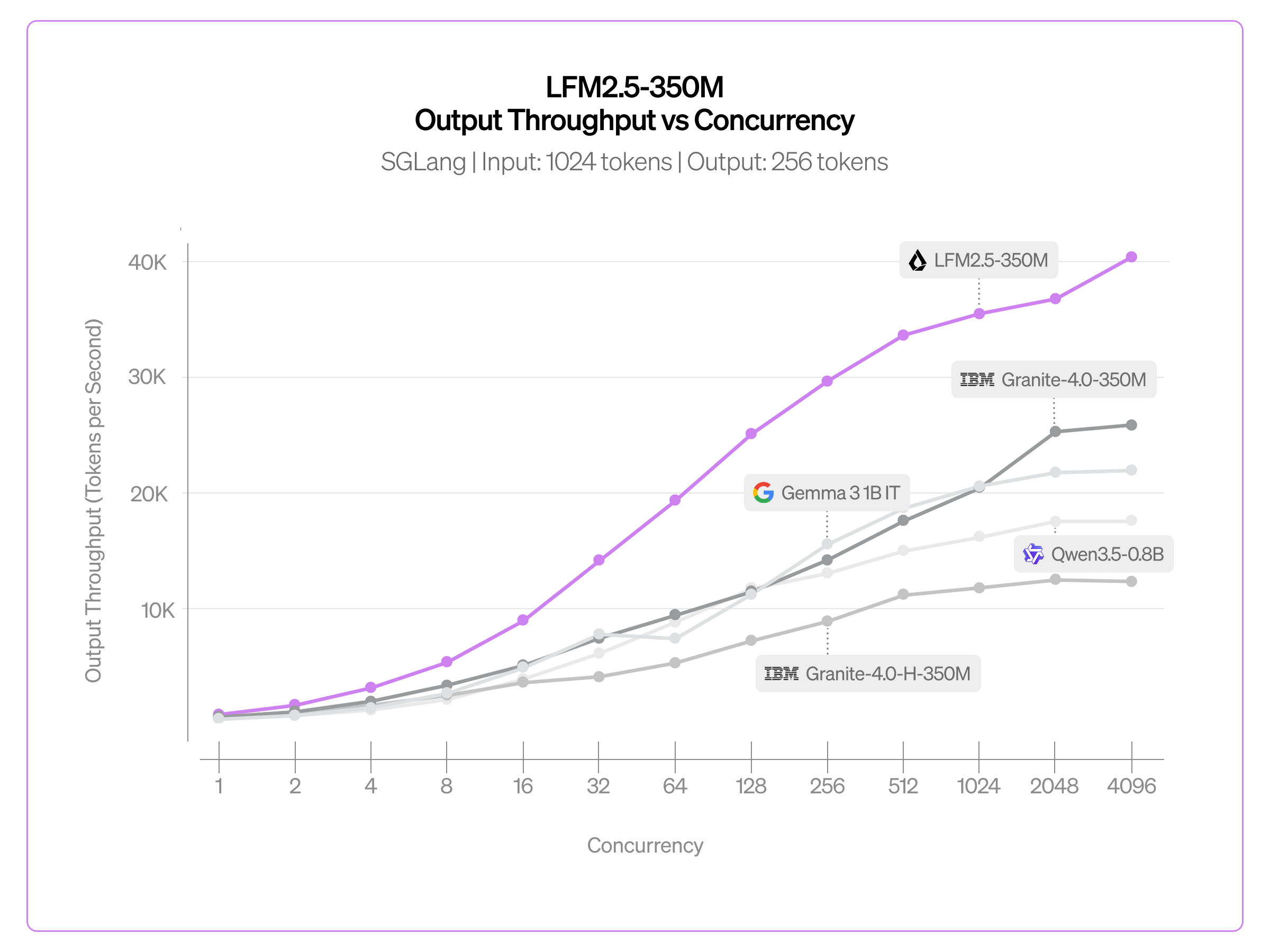
On GPU (SGLang, 1024 input tokens, 256 output tokens), LFM2.5-350M reaches over 40K tokens per second output throughput at high concurrency (4096), far surpassing Granite-4.0-350M, Gemma 3 1B IT, Qwen3.5-0.8B, and Granite-4.0-H-350M across the entire concurrency range.
Capabilities
This model is multilingual, supporting nine languages including English, Arabic, Chinese, French, German, Japanese, Korean, Portuguese, and Spanish. Liquid AI recommends using it for data extraction, structured outputs, and tool use (function calling via a ChatML-like format), while noting it is not recommended for knowledge-intensive tasks and programming. Suggested generation parameters are conservative (`temperature: 0.1`, `top_k: 50`, `repetition_penalty: 1.05`).
Use Cases
- On-device deployment and fast edge inference (mobile, edge, CPU/GPU environments)
- Multilingual tasks across nine supported languages
- Data extraction and structured outputs
- Tool use and function calling
spm https://github.com/trymirai/uzu.git
| 1 | import Uzu |
| 2 | |
| 3 | public func runChat() async throws { |
| 4 | let engineConfig = EngineConfig.create() |
| 5 | let engine = try await Engine.create(config: engineConfig) |
| 6 | |
| 7 | guard let model = try await engine.model(identifier: "LiquidAI/LFM2.5-350M") else { |
| 8 | return |
| 9 | } |
| 10 | for try await update in try await engine.download(model: model).iterator() { |
| 11 | print("Download progress: \(update.progress())") |
| 12 | } |
| 13 | |
| 14 | let messages = [ |
| 15 | ChatMessage.system().withText(text: "You are a helpful assistant"), |
| 16 | ChatMessage.user().withText(text: "Tell me a short, funny story about a robot") |
| 17 | ] |
| 18 | let session = try await engine.chat(model: model, config: .create()) |
| 19 | let stream = await session.replyWithStream(input: messages, config: .create()) |
| 20 | var message: ChatMessage? = nil |
| 21 | for try await update in stream.iterator() { |
| 22 | switch update { |
| 23 | case .replies(let replies): |
| 24 | message = replies.last?.message |
| 25 | case .error(let error): |
| 26 | print("Error: \(error)") |
| 27 | } |
| 28 | } |
| 29 | print("Text: \(message?.text() ?? "empty")") |
| 30 | } |